Deepfakes... and its threats (part 2)
- Nazar Kaminskyi

- Nov 20, 2020
- 5 min read

In our first article related to the topic of DeepFakes, we have reminded our viewers on the dangers of these technologies, the various attempts from the industry to tackle the issue (including via a recent Kaggle competition launched by a consortium of major players such as Facebook) and our own idea to explore the topic further, by leveraging segmentation neural networks to not only recognize but also characterize the fakes, through the localization of modified areas. From these localizations, we would classify both single frame and entire videos.
This article presents the outcome of this exploration. We wish you a good reading and invite you to post comments or questions, should you have any !
Data
As the main dataset in our research, we chose Kaggle DFC dataset, which is today considered as one of the largest and most complex datasets. Since the Kaggle dataset is really big we only used 40% of it for training and the last 10% part for testing. Also for additional testing of the developed models, we used videos from FaceForensics++ [c23] and Deep Fake Detection [c23] datasets. The data scheme is presented below :

Difficulties
To train our segmentation network, we needed to pull out fake masks. A naive approach to build this mask would be to measure the difference between a real and a fake image with a threshold, but we faced a lot of noise caused by data compression. Examples of this are illustrated below: the first column shows the difference between a real and a fake frame, the second column shows the fake face, the third column shows the real face and the fourth column shows a binary mask with a threshold from the difference of frames.

So, to get usable masks we blurred the real and fake image with a kernel [5x5] and calculated the Euclidean distance, then kept only the largest components which contain at least 100 points. Finally, we resized the images and masks to 256 by 256 pixels. In the end, we got the following result [1-st row: real face, 2-nd row: fake face, 3-rd row: mask]

Models
Today, one of the most popular and effective architectures for segmentation is Unet. Therefore, we used Unet-like architectures based on the Unet industrial model. For training we also made 2 configurations - Unet and Unet_v1. The difference is in the initial number of features (32 for Unet and 16 for Unet_v1) and the number of steps of convolution (5 for Unet and 6 for Unet_v1). Network diagrams:




Training
The Adam optimizer was chosen for training, because it does not require a perfect selection of learning rate, and is also suitable for “fast” learning. The parameters are given in the table.
As a loss function, we used a combined metric to achieve learning stability: Binary CrossEntropy and Dice Coefficient. You can read more about the Dice coefficient here, and the formula for the loss function is given below.
LOSS = BCE - ln(DICE)

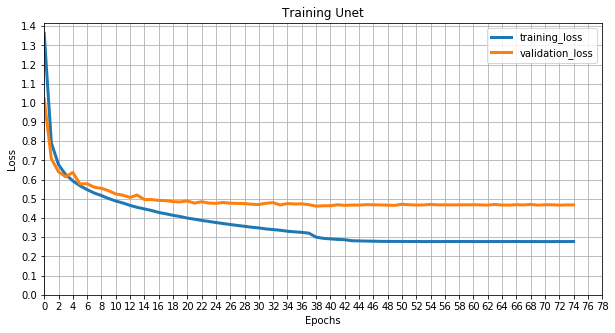

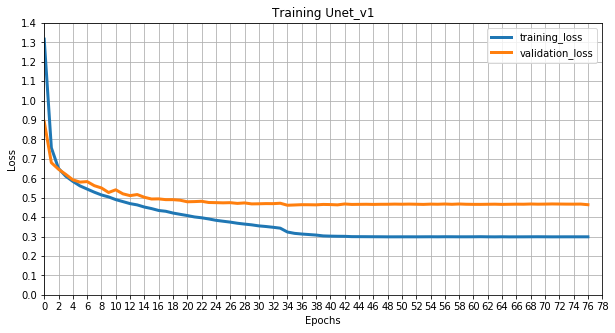
Weights for trained models can be downloaded here.
Visual results:




Result
We decided to test the obtained models on the three data sets described above, to check the generalization of the models and their efficiency. We compared the results with 2 other models: FaceForensics++ classifier (Xception) [trained on the FaceForensics++ dataset] and Efficientnetb7_dfdc [trained on the Kaggle dataset]. Unfortunately, the implementations of existing approaches for fake localization presented in [1, 2] are not publicly available now.
First, consider the results of segmentation. We use the Dice coefficient to measure model performance (we remind you that the best value is 1, and the worst is 0).
The low score is caused by a large number of incorrect fake predictions. Also, the really low value of the Dice coefficient on the Deep Fake Detection Dataset and FaceForensics++ Dataset is due to the fact that almost the entire faces were replaced in these images, while our network was trained on images where only certain parts of the face were replaced. However, despite the low value of the Dice coefficient, our network can still detect fakes as you can see above.
Based on the segmentation of our models, we will classify frames according to the frame classification rule: network confidence > threshold and connected components with more than 100 points. We selected the best threshold for Unet: 0.95 and Unet_v1: 0.5 using the grid search.
Based on the segmentation, you can also make a video classification according to the video classification rule: If more than half of the frames of a video are classified as fake (see frame classification rule above), then the video is fake. The results are below.
In the context of fake detection, precision tells us how many frames or videos are actual fakes among all the ones we detected as fakes, and recall tells us how many actual fake frames or videos stayed unnoticed (if recall is 1, it means that no actual fake stayed undetected).
Considering that we used only part of the Kaggle dataset available, and no other dataset, the results obtained are quite promising.
The classifiers give, generally speaking, better results for both frame classification and video classification, but at the same time they do not give a complete picture for fake analysis as the one that can be obtained with segmentation.
We can see that the classifiers are more dependent on the training data than a segmentation approach. Performance is greatly reduced on data from another dataset, so they do not generalize that well, and the F1 scores obtained by the segmentation network exceed the ones obtained with the classifiers in these cases.
At the same time, although our segmentation networks didn’t demonstrate the best result, they have almost the same level of performance for all three datasets, which may indicate better generalization properties.
As we can see our segmentation model obtains, in general, a better recall for all three datasets for a frame and video classification. This fact makes our model more suitable for a fake warning system, where the priority could be that a minimum of actual fake stays undetected.
Side notes
Unfortunately, there is no more access to the private datasets from Kaggle, so we can not compare these results with the Kaggle competition leaderboards.
Our experiment demonstrated that data compression has a crucial impact in the efficiency of fake detection. A large amount of noise may lead the models to study the wrong features.
Сonclusions
It becomes more and more difficult to detect fakes, and at the same time it no longer requires large computing power or know-how to create examples that can deceive people. Even a fake of poor quality can cause some negative resonance in the media.
In the future, we may not be able to distinguish fake from a real message at all (see [3, 4] for interesting discussions on the topic). As a consequence, people will need to learn how to double check information and in parallel, we obviously need more powerful tools to recognize fakes. We believe it is possible to develop a powerful fake warning system based on segmentation model as the one we used.
--------------------------------
* Follow us on LinkedIn for next blog updates:
* Interested in our skills? Let's discuss your projects together:

or
* Our public Github repository:

--------------------------------
References
Yihao Huang, Felix Juefei-Xu, Run Wang, Qing Guo, Xiaofei Xie, Lei Ma, Jianwen Li, Weikai Miao, Yang Liu, Geguang Pu. FakeLocator: Robust Localization of GAN-Based Face Manipulations. 2020. URL: https://arxiv.org/abs/2001.09598
Lingzhi Li, Jianmin Bao, Ting Zhang, Hao Yang, Dong Chen, Fang Wen, Baining Guo. Face X-ray for More General Face Forgery Detection. 2020. URL: https://arxiv.org/abs/1912.13458
Deepfake detection algorithms will never be enough. URL: https://www-theverge-com.cdn.ampproject.org/v/s/www.theverge.com/platform/amp/2019/6/27/18715235/deepfake-detection-ai-algorithms-accuracy-will-they-ever-work?amp_js_v=0.1#referrer=https%3A%2F%2Fwww.google.com&_tf=From%20%251%24s&share=https%3A%2F%2Fwww.theverge.com%2F2019%2F6%2F27%2F18715235%2Fdeepfake-detection-ai-algorithms-accuracy-will-they-ever-work
https://www.technologyreview.com/2020/09/29/1009098/ai-deepfake-putin-kim-jong-un-us-election/